We then tried to expand further with a genre-identifier, which would sort any music into six genres: qawwali, hiphop, blues, jazz, classical and rock, with another five being added later on. This classifier was trained on Mr. Faheem Sheikh’s QawwalRang database. We at first used the same method, i.e. training our model on MFCC features, as the previous project, but reported a rather low success rate. This caused us to try using the prebuilt YAMNet model to help by feeding it our data and training our classifier on its embeddings (its middle layers’ partially processed outputs). This significantly increased its accuracy, and allowed us to expand it to eleven genres: qawwali, hiphop, blues, jazz, classical, rock, reggae, rock, disco, pop, and metal..
A More Technical Perspective
The Six-Genre MFCC Attempt
For our second machine learning project, we chose to build a model which could classify music into six different genres: qawwali, hiphop, blues, jazz, classical and rock. It used Mr. Faheem Sheikh’s QawwalRang database and used 60 MFCC features for each like the instrument classifier. This model had two hidden layers, and was a TensorFlow Sequential model. The code was again borrowed from the article on using audio classification with Librosa, which is the source for most of our projects. We then modified it to work for 11 genres.
The CQT Modification
We then modified our model to use CQT features as well, as recommended by Mr. Fahim Sheikh in his article, out of a hope that they would improve its performance. These features were better suited to detecting the tabla than the MFCCs, making them a perfect choice to identify the Qawwali genre. This gave this model a small but observable advantage over the solely MFCC using model, as seen in the following graph.
The YAMNet Model
We chose to use the help of the YAMNet audio classification model, which classifies audio samples into more than 500 different classes, ranging from sirens to shouting. This model takes in a .wav file and outputs embeddings alongside its finished result, which can be used by other audio models for enhanced efficiency. We trained a simple model to use the YAMNet embeddings with the help of this article, which reported an increased dev accuracy of around 0.85 for the eleven used genres. Our database consisted of 7700 videos, each 3 seconds long, which we acquired through slicing the files obtained from Mr. Sheikh’s database into three-second clips. Before doing so, we at first used the files in their original thirty second form.
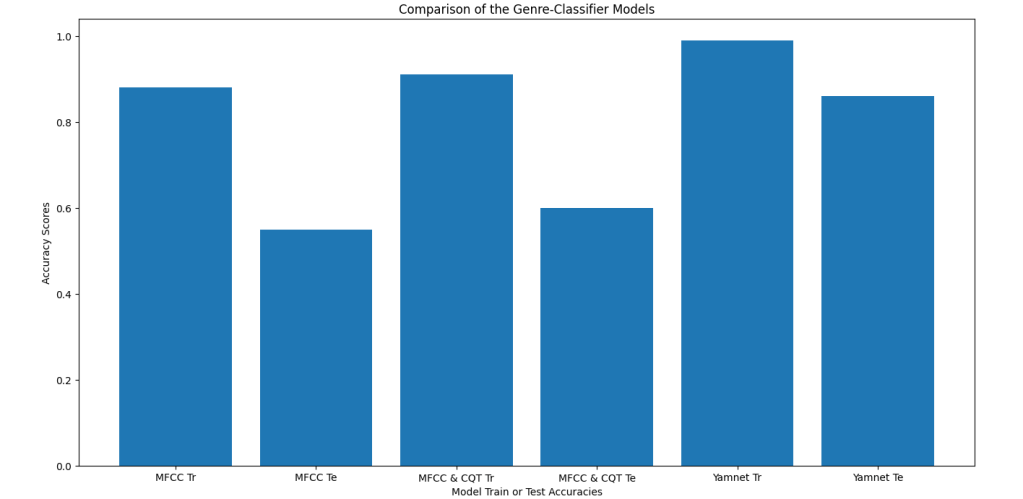
Interestingly, whether using three or thirty second clips, our model’s performance remained roughly the same so long as the total amount of data we fed it remained the same. This contradicted our belief that reducing the clip length would degrade its performance by giving it less continuous data to work with. Another surprising fact we discovered was that, as you can see above, the YAMNet model out-performed the others by a significant margin, especially in the most important category of all – test accuracy. This discovery radically changed our machine learning approach by helping us realize the sizable advantage using YAMNet gave us, and greatly influenced our following projects.
Save the Sitar is a website dedicated to promoting and preserving Pakistan’s classical music. Join our growing community to help further our cause!
Follow Save the Sitar!
Get new content delivered directly to your inbox.
